




I like to use the concept of a Pokédex (a portmanteau of “Pokémon” and “index”) to explain how best to approach information management in the context of research. For those not familiar with the term, I promise I’ll only dedicate a few paragraphs to the subject – suffice to say that in the world of Pokémon, trainers use a sort of electronic encyclopedia called a Pokédex to scan any Pokémon they encounter in the wild, during Pokémon battles or in the course of capturing and training them. This serves two main purposes:
The trainer can immediately learn whatever information about the Pokémon has been stored in the Pokédex’s database prior to an encounter.
The Pokédex is updated with whatever new data it can collect during the encounter (such as unrecognized behaviors displayed by the Pokémon), much like an automatic logbook.

Thus, trainers can refer to the Pokédex to study their opponents' Pokémon during a battle or prior to it, and they can also use it to check how best to care for their own Pokémon and discover what abilities they possess.
The interactive nature of the Pokédex allows its dual use as both a reference guide (essentially a knowledge output device) and logbook (a knowledge input device), and it is because of this electrically-enabled duality that I view it as a near-ideal model for an information management system (or IMS).
IMS in the service of research
Moving on from the Pokédex example, I should explain the value of good documentation while researching, especially when working as part of a group.
In research, we should strive to cultivate a knowledge base and make it as comprehensive and useful as possible. This entails maintaining some sort of documentation platform that facilitates the following:
Mutual learning with our current peers
Drawing on the shared experience of past researchers
Enabling future recollection by our future selves and peers
The last point is especially important, as we often cannot anticipate the operative value a piece of information will have until a later date when it becomes relevant. In the long term, documenting our knowledge can be somewhat likened to an ant leaving a pheromone trail – both are actions undertaken by an individual in the present that can have a delayed effect on ourselves or on others, and both serve as examples of stigmergy:
stigmergy (noun)
a mechanism of indirect coordination in which a trace left by an action in a medium stimulates a subsequent action.
Therefore, a documentation platform can be said to require efficient functionality across both space and time. Succeeding in this grand endeavor depends on our collective ability to effectively contribute and organize our own findings (input and processing), and easily extract existing knowledge (output).
In a sense, using a well-maintained documentation platform allows us to “outsource” our individual and collective long-term memory to something with greater storage capacity and less inclination to embellish facts over time. If you're doing it really well, you should be able to:
Confidently proclaim that the database contains everything important that we know about every subject we've ever looked into in the past, and some good starting points for anything else we might research in the future.
Simply search and copy-paste from the database the next time you're asked a question about something you’ve looked into before (with some minimal editing to account for real-time context).
Conversely, in the absence of good documentation:
The researcher forgets things, and has no technical means of compensating for forgetfulness. Moreover, they waste time attempting to recover forgotten information.
It is much more difficult to train new researchers, as they are entirely dependent on their more experienced peers to learn new information, or they waste time “re-inventing wheels”.
Research is discontinuous, in the sense that every time a researcher leaves the team, the team itself “forgets” a great deal of knowledge (compounded by the unavoidable loss of experience).
I don’t have much practical guidance to offer about how to actually utilize the documentation platform (though I’ll a have a bit more to say on this subject in a future post), other than suggesting you make two habits:
Use the platform to look up names and terms you encounter “in the wild” (this should come quite naturally).
Don’t hesitate to essentially dump references, quotes and your own initial musings into existing entries, or even create new stubs to edit and expand on sometime later (a stub can be useful even if it’s nearly empty, as it signals to your peers and to your future self that the subject has yet to be properly researched).
The ideal IMS
I’d like to describe the characteristics I believe an IMS should have in order to best facilitate research, and I’ll mention in square brackets [like this] a few examples of systems which offer at least some of these features (though please let me know about additional options I may have missed and I’ll add them as suggestions here — I’m still searching for the best system).
Note that no matter what type of documentation platform you use, how you and your research team make use of it (and how much) is usually the most important aspect. However, having a comfortable feature-rich platform will make you more inclined to interact with the platform on a regular basis, and certain advanced features might even help you reach new conclusions and fast-track your analysis.
Essential features
Formatting — the editor should support WYSIWYG [Confluence / MediaWiki] (and preferably Markdown behind the scenes) [Notion / Obsidian]. It should also have excellent support for multiple languages in the same text, via use of complex text layout (CTL) and right-to-left (RTL).
References / footnotes as both data and metadata — it should be easy to add references to specific pieces of information, and not just by manually adding numbers in superscript (Microsoft Word’s footnote support is a good standard in my opinion), and references should also be parsed and indexed as metadata [Mendeley / MediaWiki], to allow dynamic organizing (see below).
Search — this may seem obvious, but queries need to be blazing fast and highly reliable (meaning that I should be able to assume that if I’ve searched for something but couldn’t find it, that means it definitely doesn’t exist in the database). Search can be augmented by auto-suggest; search term highlighting in results; and optionally allowing for variations, such as synonyms, hypernyms, morphology and error correction (“did you mean”).
Tags / labels — I should be prompted to add tags at some point during the editing process [Notion / Obsidian / Confluence] (It’s incredibly frustrating to know that you once inputted an item but be unable to find it because you’re not sure exactly how to search for it — tags make this scenario a bit less likely to occur).
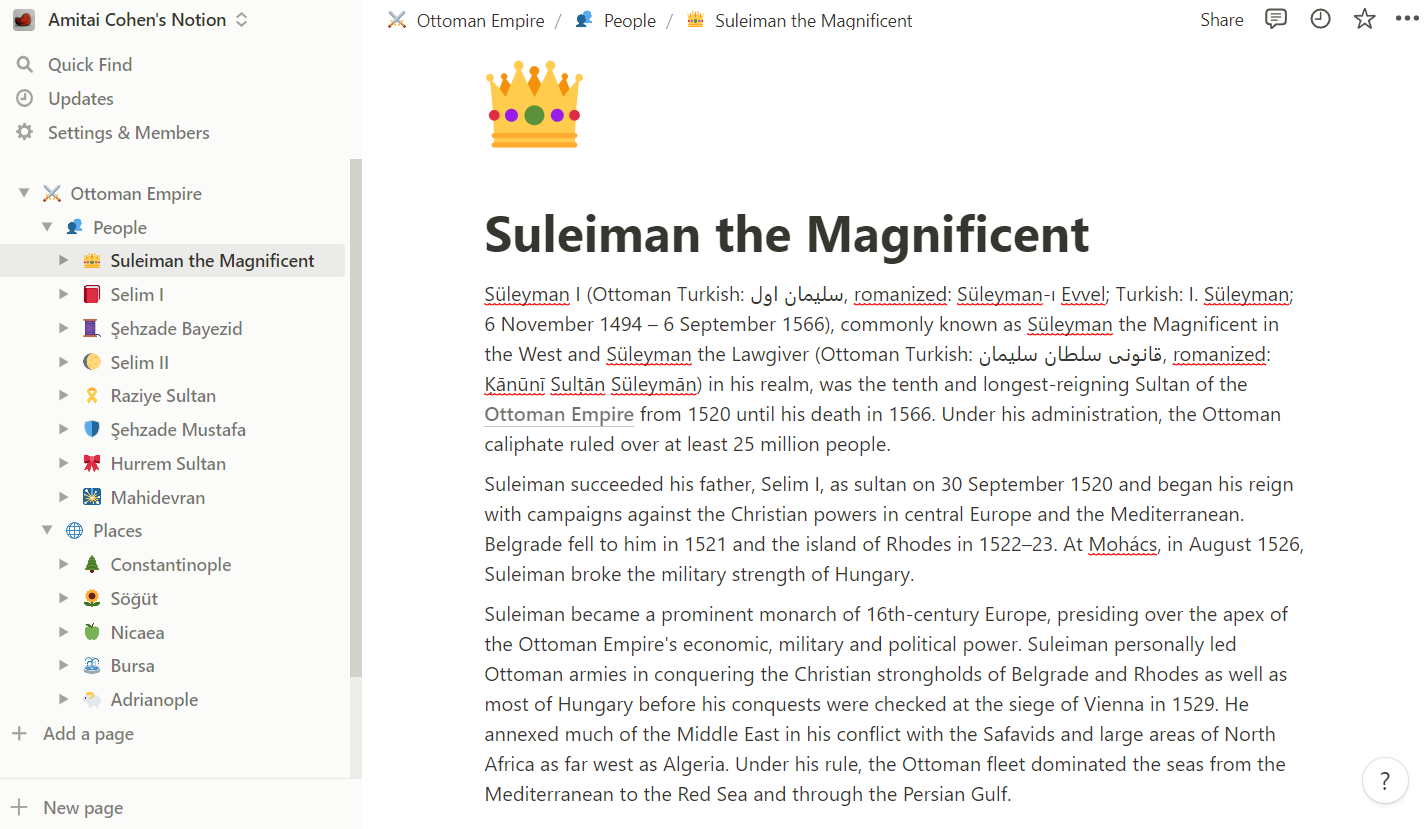
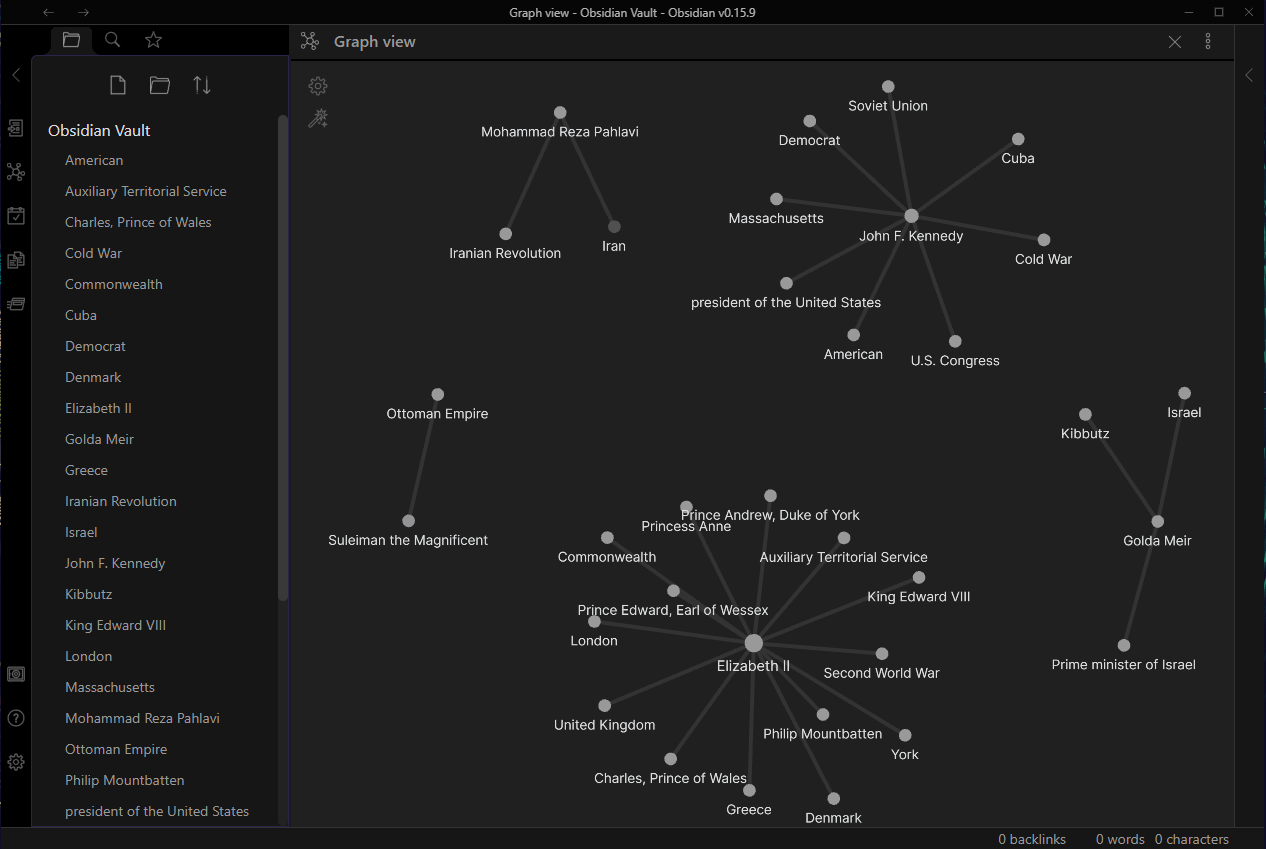
Structure — the database should support the organization of items in such a way as to allow expression of relationships or hierarchies (such as a tree or graph) [Notion / Obsidian].
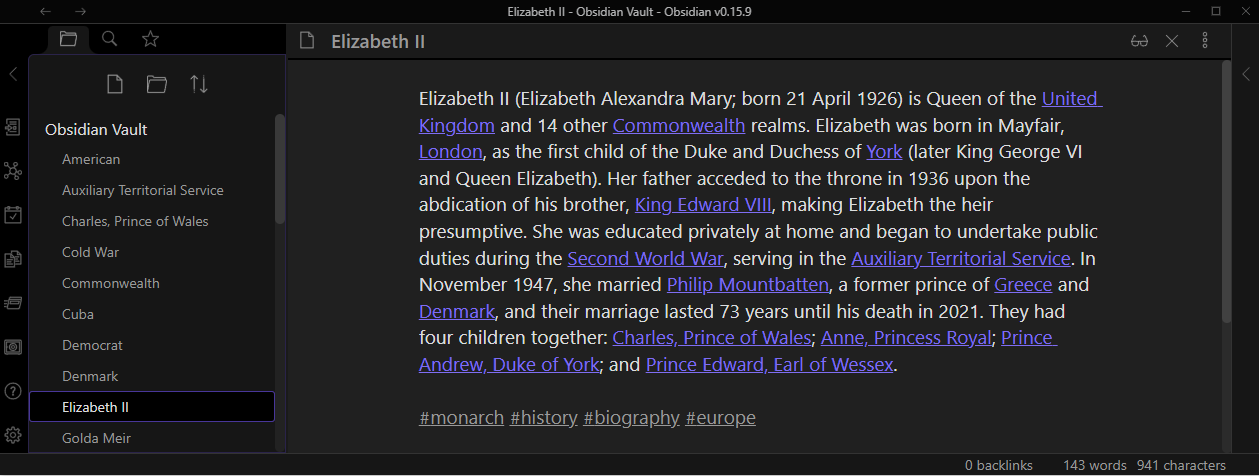
Interconnection — I should be able to link between different items in the database, and examine links and backlinks (i.e., what items link to the current item) [Notion / Obsidian / MediaWiki].
Retroactive linking - as new items are added, mentions of them in existing items should be converted to links.
Versioning / version control — records should be kept of previous versions of every item [Notion / Confluence / MediaWiki], both as a backup in case of accidental edits and to allow reflection on past paradigms and conceptions (or for nostalgia’s sake, or to simply appreciate how far our knowledge has come).
Comfort / ease of use (this one is self-explanatory, but hard to implement)
Scalability (both in terms of the number of items the database can contain without affecting search speed, and the number of users)
Optional features
Dynamic organizing principle — it would be useful to be able to change the way the data structure is presented on the fly (for example, if multiple articles in the database rely on the same references, this data could be presented as either a collection of articles or as a collection of references, depending on the user’s preference) [Mendeley, to some degree].
Tooltips — hovering over a linked item should pop up a short description of it, to make reading more efficient [MediaWiki] (this feature can greatly benefit from auto-synopsis - see below).
Semantic search — search should account for semantic information that exists within the database itself when (optionally) allowing for hypernyms in queries. For example, if the database happens to contain an entry about a king named George VI, then the results for “king” (a hypernym of George VI) should include every item that mentions George VI (along with other kings and any mention of the word “king”), whether or not he is referred to by his title in the texts.
Hyponym-tagging — the database should allow users to manually input indexes that match certain keywords with categories, so that searching for “ruler” in a history research database, for example, should return results about various kings, emperors, sultans and presidents (all hyponyms of “ruler”), whether or not their names are preceded by their title in the texts (this used to be possible in Microsoft Word via manual “smart-tags”, but the feature has since been deprecated). Note that manual hyponym-tagging can be made redundant by semantic search.
Auto-analysis — a machine learning model could theoretically be trained on the contents of the database, such that asking a question or beginning to write a sentence should produce a passable (basic) analysis.
Auto-complete — words should be suggested as I type in the editor, and the suggestion vocabulary should be based on words in the database itself rather than just including common phrases.
Auto-tagging — tags should be suggested based on an automatic analysis of content and detection of its subject matter.
OCR and attachment indexing — documents attached to database entries should be scanned and indexed to allow concurrent searching through both knowledge and information.
Collect-as-you-browse — this feature isn’t so much about knowledge curation than it is about reliable recollection of raw information encountered in the course of research, by essentially indexing everything the researcher sees [hunch.ly].
Annotate-as-you-browse — an extension of the previous feature, this basically means that markup and notes on raw information are indexed [hunch.ly] and shared among the rest of the research team.