
Querying in Research
Just keep pivoting


Research and analysis involve quite a great deal of searching for information. In practical terms, this entails querying various databases and cross-referencing with our own ever-expanding research corpus. These databases usually contain some form or another of collected information (whether raw, pre-processed or enriched), and our goal in this is usually to find specific data, answer our research questions and reach new conclusions.
The most familiar example of this process is probably the use of a general web search engine (e.g. Google), but more specialized research scenarios often involve domain-specific tools (for example, a cyber security researcher might query malware samples stored in VirusTotal by utilizing YARA, a domain-specific querying language). In any case, we can identify a common strategy - or at the very least, a common set of tactics - for querying data in the course of research.
Obviously, we can improve our chances of success with this general strategy by augmenting it with orientation (by which I mean familiarizing ourselves with the characteristics and quirks of our databases), intuition (as in accumulated experience, or perhaps research fluency) as well as some degree of creativity and common sense. Furthermore, we can streamline our queries by investing in proper organization and enrichment of our data.
The most basic element of our general querying strategy is pivoting, by which we continually proceed from one query to the next, adapting both our queries (how we search) and our goals (what we’re searching for) based on everything that we have discovered so far, and considering which avenues of research still have potential as opposed to those which have been apparently exhausted.
pivot (noun)
a shaft or pin on which something turns
the center point of a rotational system
pivot (verb)
to turn on or as if on a pivot
to adapt or improve by adjusting or modifying something
It’s best to approach this strategy without putting too much thought into where we should begin (the chicken or the egg), but rather just picking up wherever we happen to be (in medias res, so to speak). It doesn’t really matter if our actual starting point was an idea or some previous query (which may have been the result of an even earlier query, and so on) - what matters is what we know right now, and how we should use that knowledge to make the best decision on our next steps.
Our short-term goal at any given point in the process is to learn something interesting, as in information that is both new and relevant to our research. In other words, the information we’re looking for should engage somehow with our current understanding of the issues at hand - perhaps it serves to confirm something we already suspected, challenges our assumptions or surprises us. We should use each such piece of information to do one or more of the following:
Answer our research questions, by supporting or refuting a claim.
Properly record the information in our corpus for future use.
Continue our search by pivoting on the information, whether we hope to find more of the same or locate something else entirely.
Sometimes we have a specific item or piece of information in mind, or even know exactly what we’re searching for (perhaps we’re looking for a website, article or quote we’ve read before). At other times, we may only have a general idea of what we’re searching for, or haven’t the slightest clue where the information might be. Either way, it’s important to imagine how the information could be presented and visualize the form it might take in the database. Even if we end up being wrong about it, the thought exercise will often supply us with a good starting point to iterate on, and we might get it right on our next try.
Say we’ve managed to find an item of significance with interesting information (such as a webpage, document or database entry). At this point, our pivoting thought process should take into account two aspects of the item of interest:
Content:
What is it about?
What names does it mention? (e.g. people, places, things)
How exactly does it refer to them? (note the use of nicknames or technical terms)
What unique identifiers does it contain? (e.g. catalog numbers, CVEs)
Metadata:
What is it?
What is it called?
How is it structured?
Who made it?
When was it created?
Where did we find it?
Where did it originally come from?
Each of the answers to the above questions can be used to finetune or revamp our next queries, by either broadening, narrowing or shifting the scope of our search, depending on what we hope to find. At each juncture, we should keep in mind two complementary measures of quality for our query, which can help us decide if our scope is too broad, too narrow or completely off the mark:
Recall - how many of the sought-after items are included in the results?
Precision - how many of the items included in the results are sought-after?
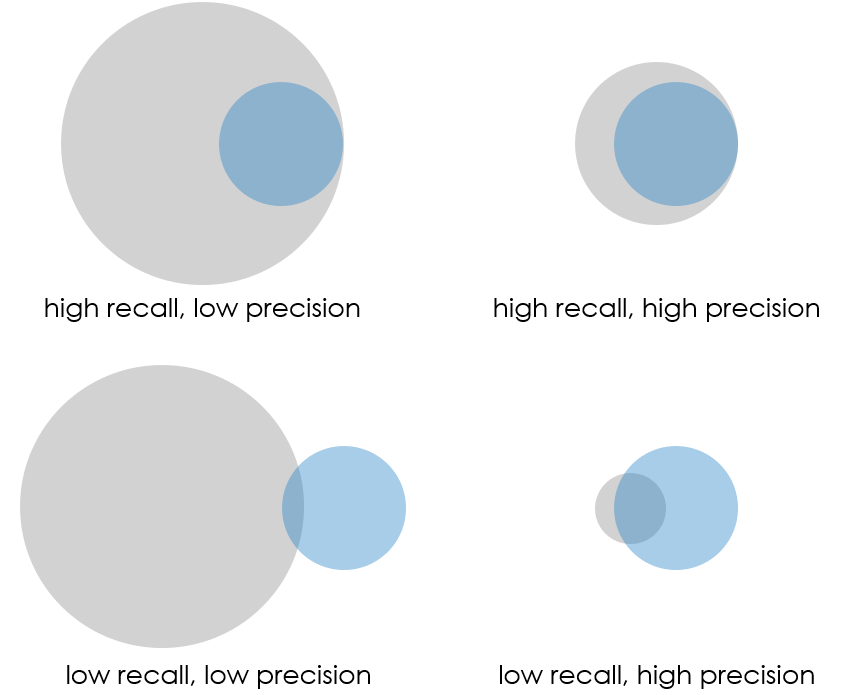
Our assessment of these factors need not be scientific or exact. Instead, its usually best to just get a feel for the results and make a snap judgement on how to proceed. For example, if our query returns too many results for our liking, or if the first few results seem irrelevant, we can simply assume that the precision is too low and adjust our query accordingly. Conversely, if our query returns too few results, none of which seem relevant (except perhaps for items we’ve already located), then we can surmise that the recall is too low and that we should try something else.
If we’re looking for more of the same (such as additional articles written by the same person, or documents in the same format), we must identify the item’s unique characteristics (from both a content and metadata perspective). This entails recognizing what makes the item special or rare in comparison to most other items in our databases, and what properties it probably shares with similar items (i.e. in what way we expect them to be similar; such as tables sharing the same field names but containing different sets of data). Then, we can intersect these attributes in our queries (with AND operators) to more easily locate other items of the same type. Conversly, if we wish to remove similar items from our quety results (such as documents in a particular format that aren’t of interest to our current research), we can exclude these attributes in our queries.
Otherwise, if we intend to find different types of items that somehow relate to our current one - such as others touching on the same subject - then we need to extract leads that we can follow up on, or “threads” we can pull, in our next queries.
Either way, our general strategy at any given point in the process will involve:
Extracting leads or attributes from the interesting item, in the form of both metadata and content, and adding them to our existing query “vocabulary”.
Building a new query, or finetuning a previous one, by:
Including promising leads.
Including certain “helper” components (see below).
Excluding noise indicators (with NOT operators), such as words that often show up in items that we’d like to filter out of our query results (these indicators can often be just as valuable as good leads).
Executing the query:
If the precision seems satisfactory, browsing through the results until we find an item of interest, and [go to step 1].
Otherwise, [go to step 2].
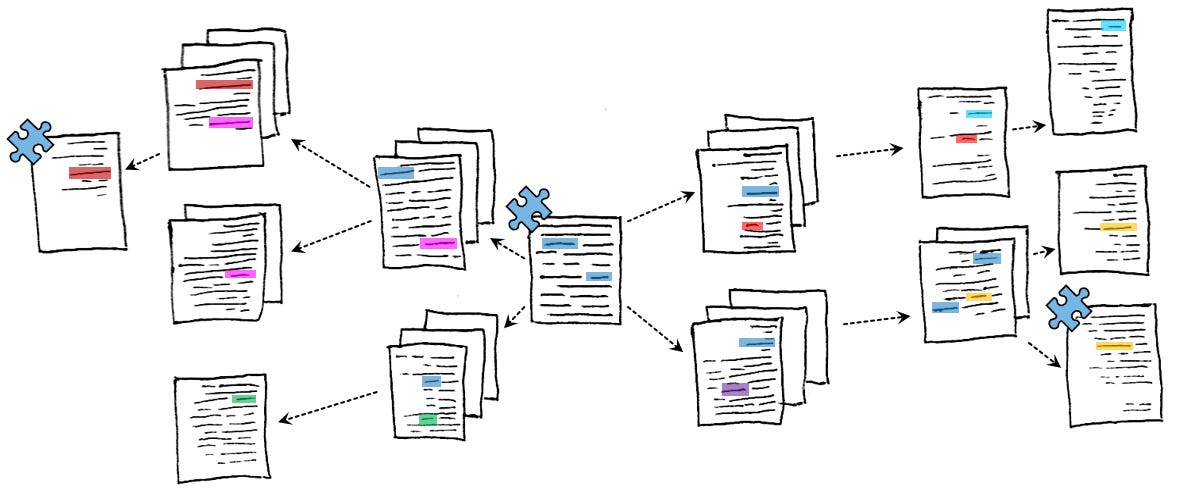
The halting conditions in the algorithm outlined above are somewhat difficult to precisely define, but we should generally move on once we’ve (optimistically) discovered enough interesting information or (more realistically) once we feel that we’ve run out of ideas or exhausted our databases. Often, it’s best to simply try again at a later date, once more data becomes available or we come up with new ideas.
As mentioned above, we can make excellent use of “helper” components in our queries in order to improve recall and/or precision, namely:
Synonyms of the words we’re looking for (preferably while using an OR operator)
Words in the same semantic field (e.g. “driver” or “garage” in relation to “car”)
Hypernyms (generalizations, e.g. “vehicle” in relation to “car”)
Hyponyms (specializations, e.g. “Toyota” in relation to “car”)
Co-hyponyms (e.g. “tractor” in relation to “car”, as both are types of ‘‘vehicle’’)
Meronyms (smaller parts, e.g. “tire” in relation to “car”)
Holonyms (greater wholes, e.g. “fleet” in relation to “car”)
Collocates (words that often appear together, e.g. “driver” in relation to “car”)
For a given word, we can use a thesaurus or tools such as WordNet to help us discover other words in the same semantic field, including synonyms, hypernyms and hyponyms.
Including these “helper” components (sparingly) in our queries allows us to detect items that would be otherwise hard to spot, due to their potentially unexpected inclusion of variations on certain words (in some cases, our unaugmented queries would miss these items entirely).
Collocates in particular are very useful for narrowing the scope of our queries to specific domains in order to improve precision (for example, we could differentiate between “virus” in the medical sense and the computer science sense by including either medical collocates such as “antibody” and “prescription” or computer science collocates such as “vulnerability” and “executable”). Alternatively, we could (carefully) exclude collocates related to irrelevant domains in order to denoise our query results.

In closing, a few words of advice:
Pivot between different databases, and avoid fixating on a single database.
Adjust your querying strategy according to the characteristics of each database.
Consider that others may have recorded and organized the information you seek in ways that seem counterintuitive.
As a rule, quantity is more important than quality (an unpopular opinion, to be sure):
It’s okay to compromise on low precision and sift through many results, as long as we’re quite confident in our recall (otherwise we’re at greater risk of wasting our time).
While we should hope to find “holy grails” in our data (as in a single piece of information that answers our research questions), it’s more feasible to discover lots of smaller bits of information that we can piece together to reach an important conclusion - we must not let this discourage us.
Some items we encounter are valuable for the information they contain that pertains directly to our research efforts, whereas some items are primarily useful for pivoting purposes (i.e. growing our query “vocabulary”, for either inclusion or exclusion), or for honing our orientation by teaching us about the data itself.
Record (or rather, hoard) the information you discover by adding it to your corpus while including the exact source (so you can return to reexamine it later and also use it as a reference in your research products), as well as any notes on ideas or possible connections to other pieces of information you’ve encountered so far. Additionally, you should tag the information so that you can more easily retrieve it from your corpus at a later point in time.