TL;DR: Since threat hunting is conducted both within defended networks and beyond their perimeters, not all observables listed in threat intel reporting should be labeled “IOCs”. Many of them don’t actually indicate compromise, so their value for threat detection is limited, while remaining useful for discovery of attacker infrastructure and attribution.
Background
The common currency of threat detection is made up of IOCs and TTPs, short for “Indicators of Compromise” and “Tactics, Techniques and Procedures”, respectively. The first mainly deals in unique artifacts that can be observed on compromised machines and are therefore indicative of compromise (hence their name), while the second concerns the malicious behavior of threat actors viewed through the lens of the methods they choose to employ in order to achieve their goals, such as gaining initial access to a target environment, moving laterally within a network or exfiltrating sensitive data.
The theory that makes IOCs and TTPs useful in practice is essentially that these artifacts and behaviors can be defined in such a way as to be distinct enough from legitimate activity in a given environment that malicious actions (or at least suspicious ones) stand out in logs, and can therefore be identified through database queries or with the help of tools like YARA and Sigma. The application of this theory is an important facet of detection engineering.
Sometimes this idea is applied in the service of widescale detection, such as when implemented in an Endpoint Detection & Response product (EDR), which involves searching through a large dataset of logs collected from many machines with the goal of surfacing potential incidents. Other times it’s used for forensic analysis, to confirm suspected compromise or to better understand what occurred within a known-compromised environment. Moreover, if a threat actor is using a specific enough set of tools while exhibiting a specific enough set of behaviors, then in some cases this practice can also support attribution.
However, in the context of threat hunting – especially when said hunting extends beyond the perimeter of a defended network and crosses into the wider Internet – we begin to encounter certain types of indicators that don’t necessarily fit neatly into the strict definition of “IOC”. This is because they either aren’t indicative enough (they’re simply too noisy to serve as detection rules without additional context) or because they don’t strictly indicate compromise. I’d like to dig into the latter case a bit.
Lumps of indicators
Probably the most popular framework by far for discussing TTPs is MITRE ATT&CK, which delineates threat actor behavior across the various phases of a cyber operation, from reconnaissance through initial access all the way to exfiltration and impact. I dare say that ATT&CK is a mature and well-defined framework, with new techniques describing novel malicious behavior regularly added to MITRE’s database.
However, I think this state of affairs isn’t quite the case for IOCs, which have been somewhat neglected in terms of practical categorization. ATT&CK and equivalent frameworks can be useful for defining which techniques a given IOC relates to, but they don’t necessarily help someone understand where and how any given IOC should be put to work.
Furthermore, rigorous formats do exist for sharing IOCs along with descriptive metadata (such as STIX), but when it comes to public threat intel reporting, as an industry we seem to have developed a tendency to just lump all types of indicators together in the appendix of a report without much distinction between them. In my experience, this makes it harder for threat intelligence consumers to make the best use of indicators, and is a form of passing the buck.
Searching in the right context
Something that has been on my mind recently is the common use of the term IOC to describe observables which, although related to malicious activity, don’t indicate compromise per se. These indicators simply aren’t meant to be observed anywhere within a target environment, but rather elsewhere in cyberspace, such as on attacker-controlled servers.

As such, they probably shouldn’t be called “IOCs” at all. In my view, this isn’t just an issue of terminology, and I don’t think I’m being unfairly pedantic, since this confusion probably ends up wasting time across many organizations.
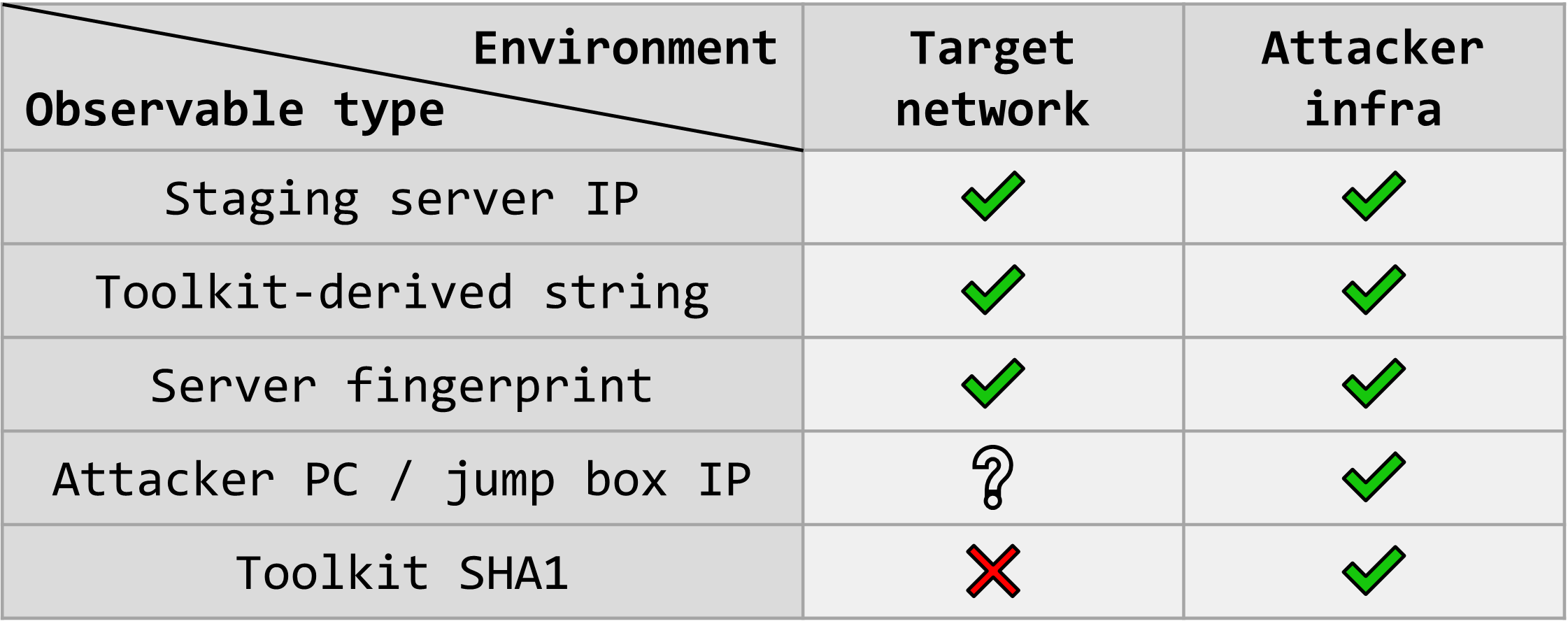
As an example, let’s say that a researcher discovers an open directory on a web server used by a threat actor for staging their activity (this happens more often than one might think). Let’s say that this server happens to contain various logs as well as tools for crafting and sending phishing messages to potential victims.
There are several things of value that could be extracted while reviewing these files, some of which might also be worth sharing externally:
The IP address of the server.
The method by which the researcher discovered the server in the first place, shared in the form of a JA3S or HHHash fingerprint.
IP addresses listed in the access logs, which might represent the threat actor’s workstation (or jump box).
Samples and SHA1 hashes of a bespoke phishing toolkit developed by the threat actor.
Additionally, perhaps the researcher succeeded in reverse engineering the toolkit and discerned certain unique artifacts such as a string that is erroneously included in every email message generated by this toolkit.
Operationalizing observables
Once all this information is disseminated through a threat intel report (publicly or privately), recipient organizations are now tasked with deciding if the activity described in the report is relevant to their threat model. If so, then their next step would be making use of the IOCs to search their environments for evidence of attempted or successful compromise (the threat report might include TTPs as well, but those are outside the scope of this post).
This process entails translating the various IOCs into detection rules, and then checking network logs for evidence of communication with the server IP address and scanning email servers for any messages containing the aforementioned string. Any of these might indicate that an organization was targeted by this threat actor, perhaps successfully.
One could argue that the server fingerprint also has value to defenders as an IOC, since organizations could theoretically conduct their own scans of any servers communicating with their network and check if they match the fingerprint, or look them up in a scan result database such as Censys or Shodan.
The IOC value of IP addresses suspected to be associated with the threat actor’s workstation (or jump box) would depend on the attacker’s modus operandi; if they never connect directly to target networks, then potential victims couldn’t effectively utilize these addresses for detection. Having said that, the attacker might make a mistake at some point, so it would be best to treat these addresses as IOCs anyway.
However, unlike all the above indicators, the SHA1 hashes of the toolkit itself are not especially useful for most organizations, since they are only likely to be observed outside a target environment, namely on the attacker’s infrastructure (e.g., other staging servers or the threat actor’s workstation), unless they just happen to work for an organization scanning their networks for these IOCs.
The only organizations that are likely to have any sort of access to non-victim environments are other security researchers (and perhaps intelligence agencies tasked with counter-cyber operations), and they can certainly make use of this information to advance their research efforts. However, public sharing of non-IOC observables is problematic, since in some cases their publication might end up being more helpful to threat actors than to defenders, especially if the former can make simple adaptations to avoid future detection (like fixing the bug that caused the unique string to be included in every phishing email).
In short, producers of threat intel reporting can make their reports easier to consume by differentiating between IOC and non-IOC observables. This makes reports more properly actionable for the audience, who can prioritize the most relevant indicators for threat detection.
Exothrunting!
In ATT&CK terminology, non-IOC observables often relate to techniques included in the PRE Matrix, which covers reconnaissance and resource development. However, some “pre-attack” observables can be IOCs, such as a user agent utilized by a threat actor during recon when scanning a target network’s public IP ranges for vulnerabilities and misconfigurations; or a directory in the threat actor’s development environment which might show up as a PDB string in a malware executable. If an observable has a chance to show up somewhere in an organization’s logs, then it should certainly be considered an IOC.
This brings me back to my earlier point, which is that existing frameworks might be good for describing the malicious behavior that an observable indicates (e.g., scanning for vulnerabilities, generating phishing messages, or developing malware), but not necessarily where and how that observable is likely to be observed by defenders, if at all.
I don’t especially want to suggest yet another framework to solve this problem (since I might be the only person bothered by it), but I am sometimes inclined to invent jargon that no one but me will ever use, so I will say that the best solution I’ve come up with so far is to simply distinguish between observables fit for internally-focused threat detection (IOCs) and those applicable to externally focused threat hunting, which I’ll call exothrunting, thereby making these non-IOC observables exothruntables (but this term is incredibly ridiculous and I only mention it here because I find it amusing).
Anyway, another way of viewing the distinction I’m trying to make here is through the lens of a client-server model – some observables are “client-side” (only likely to be observed in the victim’s environment, and therefore considered IOCs) while others are “server-side” (in the sense that they’ll only ever be found in the threat actor’s own environment). However, this distinction can fall apart if the threat actor happens to make a useful mistake, such as uploading their tools to VirusTotal for testing purposes.
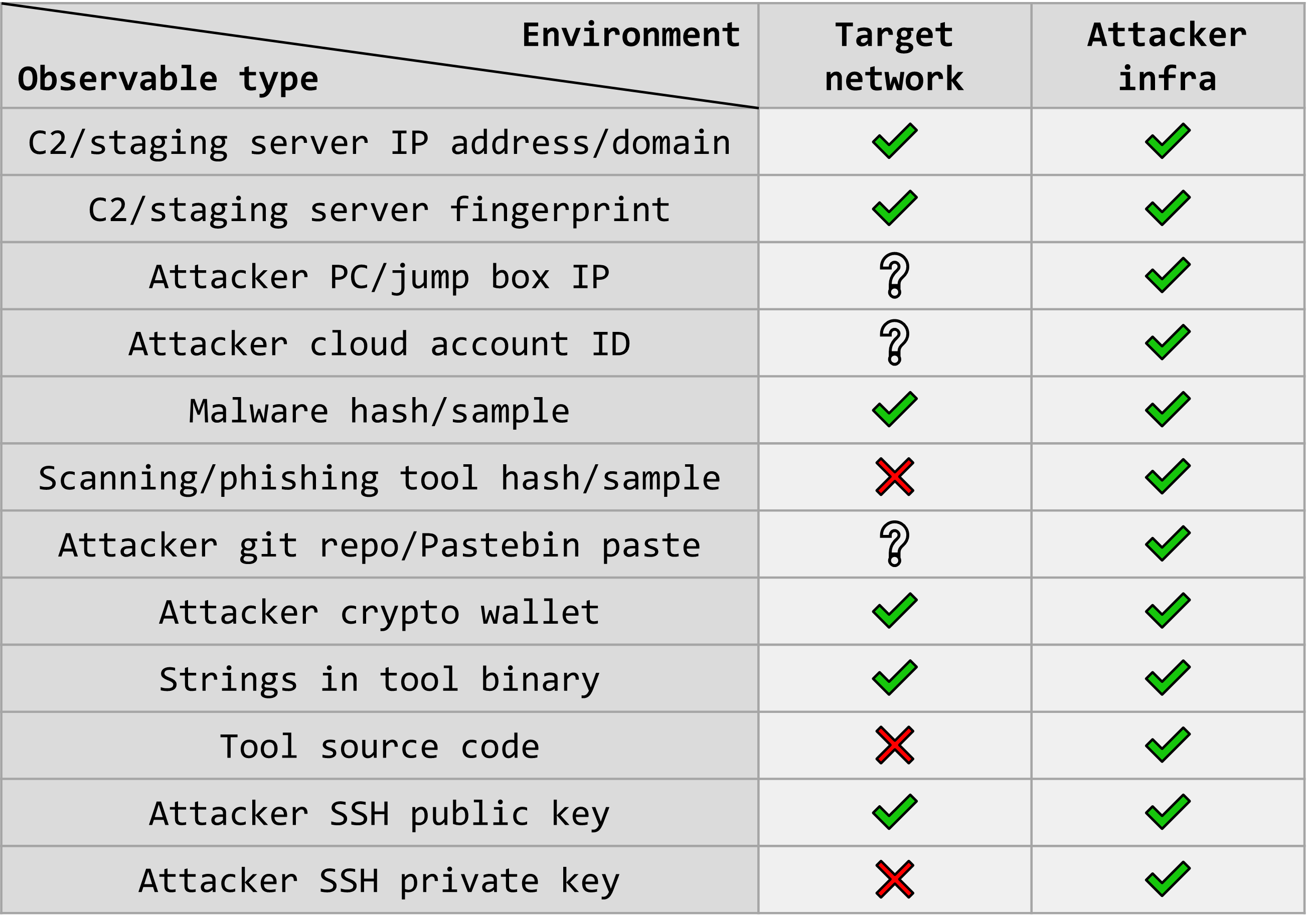
Finally, I’ve included the following table with additional examples of observable types where this distinction might make sense, and I hope others find it useful. Note that there’s further nuance to be explored here in terms of which specific types of logs in a target network are relevant for detecting each type of observable (e.g., a C2 domain might show up in DNS logs; a malware hash would be detected through an endpoint disk or memory scan; an attacker’s cloud account ID can appear in cloud logs such as CloudTrail, etc.).