
Intelligence Failure in Threat Detection
False negatives in our grasp of the fabric of spacetime

TL;DR: Analysis and operation both necessitate prioritization, but this introduces the risks of surprise and inadequate response. We can compensate for these risks through self-reflection, by asking ourselves hard questions about any given unlikely yet disastrous eventuality: “Would we know if it was about to happen?”
Given recent events, I’ve been thinking a lot about intelligence failure. Among other things, I’ve been considering how it might relate to threat intelligence and detection engineering, where failure could result in threat actors successfully compromising an otherwise well-defended target and achieving their goals.
This post started off as a way to organize my thoughts, but developed over a period of several weeks into a slightly rambling (and somewhat metaphoric) treatise on dealing with false negatives.
Introduction: estimating adversary movement
Defenders are expected to continuously gather information about (1) what threat actors want, and (2) how they go about getting what they want. We’re meant to make use of this knowledge to implement effective mitigations and detections to stop bad things from happening, react to them when it still matters, or at the very least, make the outcome less bad. In practical terms, this involves installing preventative and detective security controls at key choke points throughout the defended network, and ideally architecting the network itself to be more robust to malicious cyber activity.
One way of thinking about this is imagining the various “moves” (as in Chess) that a threat actor might make through each stage of the ATT&CK matrix (or cyber kill-chain, or targeted attack lifecycle), and applying impediments to either reduce the likelihood of success of any given move or eliminate the possibility of performing it entirely (which isn’t always an option, and might come at the expense of required functionality).

For example, one impediment might take the form of a firewall rule to block initial access to Internet-facing devices; while another might segment the network and limit access to a particularly sensitive subnet to only a specific set of users in order to prevent lateral movement between environments; and another might block outgoing connections to prevent traditional means of exfiltration. If any of these impediments should fail, or if a threat actor finds a way to bypass them, we must be able detect that a “move” has occurred, preferably as soon as possible after it happens, so that we can take responsive action such as disabling external access to a compromised user or limiting their privileges within the network.
Planning effectively for such scenarios requires that defenders have a strong grasp of both space and time, meaning that they understand the architecture of the defended network and the timeline of a potential security incident. Network architecture is a relatively solid, albeit complex and dynamic thing, but from a defender’s perspective, an offensive cyber operation is a fuzzy, branching, not-quite-deterministic series of events playing out against the background noise of many other normal benign events.

The implications of branching timelines
In the context of detection engineering, the embedded uncertainty of threat analysis can lead to both false positives and false negatives – each of which are equivalent to intelligence failure (more on this later). There are in fact many ways defenders can fail in the context of both threat intelligence and threat detection:
Failure modes related to threat detection:
Failure of observability – e.g., we didn’t realize that a certain device is installed in our network, or we weren’t collecting any logs from it.
Failure of utilization – e.g., we were collecting logs but didn't have detection rules in place to take advantage of them; alternatively, our rules were faulty (leading to false negatives / positives).
Failure of analysis – e.g., our rules were successfully triggered by malicious activity but we didn’t evaluate the results correctly, or we didn’t understand their significance.
Failure of action on analysis – e.g., our rules were triggered by malicious activity and we even realized what was happening, but our response was too slow.
Failure modes related to threat intelligence:
Failure of source development – e.g., a threat actor was planning to compromise our network, but we didn’t have any relevant sources that could shed light on their activity, nor could we determine what tools or techniques they were employing.
Failure of utilization and/or analysis – e.g., we gleaned information from our sources about the threat actor’s activity, but failed to deduce indicators of compromise that could have alerted us to the actor’s presence in our network.
Failure of action on analysis – e.g., we knew that a threat actor was actively exploiting a vulnerability that affects a certain product in our network, but for whatever reason we didn't patch it in time.
Beyond threat intelligence and detection engineering, Chris Sanders touches on the subject of branching timelines in relation to forensic analysis as well – once a potentially malicious event has already been observed via detection, we should conduct investigative forecasting. As Chris explains, this involves building a hypothesis by asking (1) what actions might have led to the observed event and (2) what actions might follow them. Then, we perform further forensic analysis, aiming to either confirm or refute our hypothesis and thereby figure out if an incident has truly occurred (i.e., a true positive), and if so, how the adversary gained access to the compromised system and what else they did from that point onwards.

Returning to detection engineering, the same principles can be applied here as well, but at a much larger scale – every potential initial access event could branch into one or more privilege escalation events, branching in turn into any of several lateral movement events, and so on. We can build detection rules by recognizing causality and correlation relationships between potential events (while differentiating between necessity and sufficiency): if A leads to B which then leads to C, then detecting B could be equivalent to detecting both A and C.

For example, let’s say our network contains an account with access to a database, and the account is protected by a strong password. This means that in order to gain access to the database, one must first authenticate to the account, which requires knowing the password in advance (let’s assume that the password is strong enough that brute-forcing it would be unlikely). Therefore, if we observe a threat actor successfully authenticating to such an account, at that point we can confidently deduce that the password is likely to have been compromised, and that we should therefore lock down the account, investigate where the password might have been stolen from (since the source is likely to have been compromised as well), and check if the account has recently accessed the database.

However, in reality things are rarely so simple – multiple accounts might have access to multiple databases in the network, and the password for each account might be stored in multiple locations. Furthermore, the database might be hosted on a machine affected by a vulnerability, allowing an attacker to bypass authentication altogether. As a result, just because we observe a suspicious event related to a certain account doesn’t necessarily mean we can clearly deduce what actually happened prior to the event or what will occur after it.

The trade-offs of time travel
The further back in time we begin our analysis, the less certain our forecasts become, leading to a greater chance of a false positive. We can’t warn against every single eventuality, because our organization only has so many resources to invest in monitoring efforts. We also cannot adequately prepare to effectively respond to every single potential occurrence, whether or not we’re capable of detecting that it’s about to happen (or has already happened). Conversely, if we begin our analysis further forward in time, we can reach greater certainty and higher levels of detail, but we will also have less time to prepare, thereby minimizing the actionability of our analysis and our impact on decision-making.

For instance, learning about a ransomware attack when the attacker has already left a ransom note is obviously far too late; identifying a breach within minutes and understanding the significance of what we’re observing allows time for an effective response but might not always prevent the threat actor from achieving their goals; identifying reconnaissance activity against an Internet-facing network device allows time for hardening it to prevent follow-on activity; and realizing ahead of time that the device isn’t properly secured would probably be the best outcome of all.
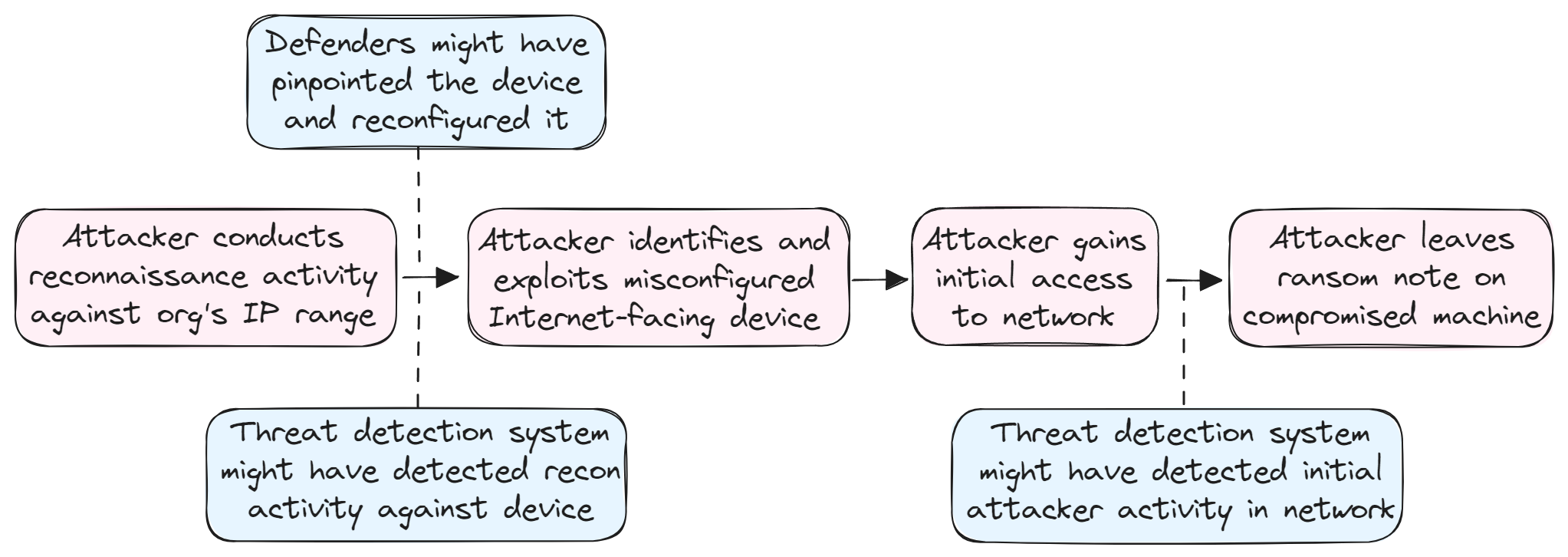
However, we can’t always know in advance that any specific device we decide to harden would have otherwise been compromised, just as we can’t necessarily know which of many such devices threat actors will eventually choose to compromise (perhaps all of them, or maybe only those included in the adversary’s evident reconnaissance activity). We also can’t know how threat actors will choose to respond to our precautionary measures if they do prove effective at hindering their malicious activity – adversaries might just try to pursue a different attack vector, such as phishing an employee or researching a 0day vulnerability in the network device.
Regardless, by mapping eventualities, we can better identify choke points or bottlenecks for proper placement of mitigation and detection mechanisms. For instance, if most paths an adversary can take all lead through the same device within the network, or require them to perform a specific action, we can treat these as a sort of singularity in which an attacker could potentially be “trapped”. Moreover, we can try to identify series of bottlenecks wherein an adversary’s movement will be predictable, bordering on deterministic.
Even if we do manage to map as many potential movements as possible, no matter how familiar we are with the layout of our network and threat actor profiles, there will always be some unknown-unknowns manifesting as “fog of war”. As a result, the actual graph of actor “moves” (in red) and their complementary detection/prevention opportunities (in blue) might look something like this, enveloped in fog to some degree:
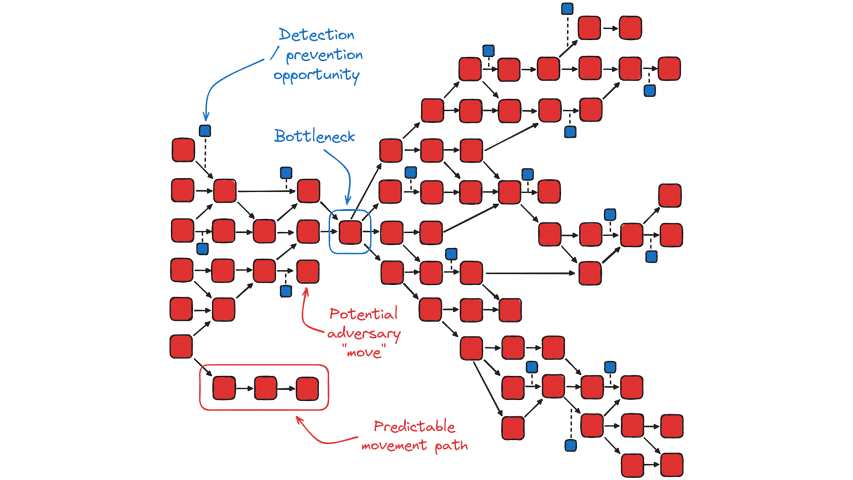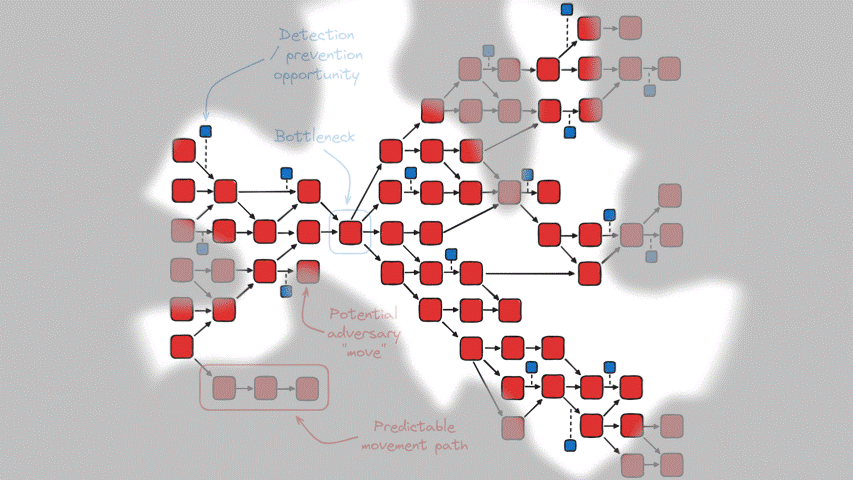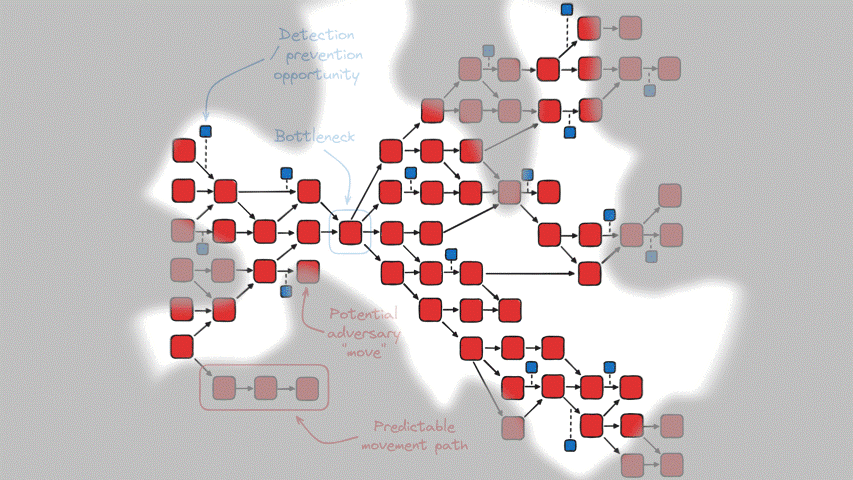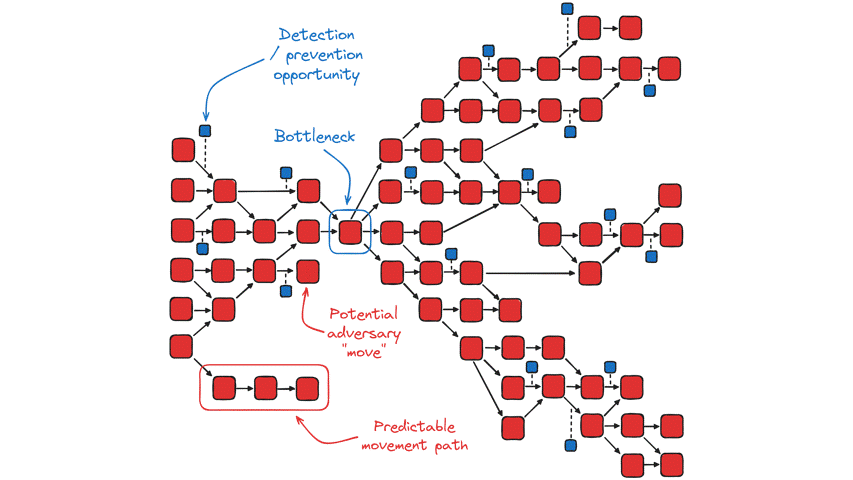
On the subject of bottlenecks, John Lambert has discussed a similar idea in relation to detection, which is that defenders can “time travel” through logs in search of bottlenecks in the kill chain – these are cases where a given technique has relatively few modes of expression, meaning that there are only so many procedures by which a threat actor could go about performing the action.

As a side-note, one could interpret the very existence of such bottlenecks in attacker behavior as a sign of “convergent evolution” of different threat actors in certain areas of operation. In such areas, we might be able to identify these commonalities and use them to our advantage (so long as they exist) when building detective and preventive controls and in the course of investigations. In Daniel Dennett’s book on evolution, “Darwin’s Dangerous Idea”, he refers to such commonalities as “forced moves”:
In chess, when there is only one way of staving off disaster, it is called a forced move. Such a move is not forced by the rules of chess, and certainly not by the laws of physics (you can always kick the table over and run away), but by what Hume might call a "dictate of reason." It is simply dead obvious that there is one and only one solution, as anybody with an ounce of wit can plainly see. Any alternatives are immediately suicidal.
[…] So at least some "biological necessities" may be recast as obvious solutions to most general problems, as forced moves in Design Space. These are cases in which, for one reason or another, there is only one way things can be done.
Prioritization, self-reflection & compensation
Threat intelligence allows us to understand how threat actors operate, which enables us to assign greater likelihood to some sequences of potential events over others. This ultimately lets us focus on what matters most and invest resources in detection and prevention efforts that actually work. In other words, threat intelligence enables better prioritization. However, we must always remember that prioritization carries risk, and risk must be compensated for.
Returning to the subject of intelligence failure, false negatives (such as failing to warn of a surprise attack) are understandably perceived as worse than any false positive could ever be, since misdetections are so tightly coupled in both space and time with their effects on reality, whether they result in disaster or a mere near-miss. There is almost certainly an emotional component to this as well, as expressed by the defender’s sense of guilt.
However, surprises are never the result of simply ignoring a source of data, but rather prioritizing some sources and paradigms over others. In other words, surprises are caused by investing too much of our attention (to a lesser or greater degree) in the wrong place at the wrong time, and anticipating the wrong outcome. But that doesn’t mean that our attention was entirely wasted, or that we should have ignored the eventualities that we did decide to prioritize. In all likelihood, whatever preventative and detective measures we did have in place were successful until they ceased to be so, and for as long as were effective, they most likely forced our adversaries to adapt.
Conversely, the direct and indirect effects of a false positive are often harder to determine, but they always manifest in the way we choose to react to them. Learning the wrong lesson from a false positive and shifting too much of our focus from one area to another could end up being the very thing that precipitates an eventual false negative. This is because our reaction to a false positive, perhaps due to alert fatigue, will often involve a change in our level of trust in the source (i.e., a change in our attitude towards the instrument, person, or organization that has cried wolf one too many times). In the context of adversarial relationships, this is a dynamic that threat actors can abuse to our disadvantage via deception efforts.
Unlikely occurrences, even if they have been justifiably deprioritized, can still be incredibly impactful, and they therefore cannot be entirely ignored. At first this might seem contradictory – isn’t the whole point of intelligence to grant us insight into adversarial activity and prioritize our defenses against the most likely of scenarios? How can we possibly deal with every single risky eventuality? The solution to this dissonance begins with self-reflection and must culminate in some sort of compensation, as mentioned above.
To compensate for the risks entailed by (unavoidable!) prioritization, defenders must routinely ask themselves a critical, difficult, self-reflective question in regard to disastrous eventualities that are considered unlikely under the reigning paradigm: “Would we know if this event was about to happen?”.
If the answer is yes, we should consider how we might know about it (i.e., through what source of information), and how early we would know (and particularly, if this would be early enough to react effectively). If the answer is no, we must compensate through one or more of the following measures:
Reprioritize in order to change our collection posture (at the expense of other efforts which might be equally important), in such a way as to either:
Reduce the likelihood of a false negative (i.e., not be surprised).
Understand enough about how the scenario will play out in order to prevent it from occurring (via preventative security controls).
Make sure that we’re sufficiently prepared to deal with the scenario in real time even if we’re surprised (via detective security controls and break-glass procedures).
Properly balancing our investment of resources in every identified eventuality is very difficult to pull off, and it requires a great deal of bravery on the part of the individuals involved. Small mistakes will happen (both false negatives and false positives), but they should be treated as precious learning opportunities and precursors to larger avoidable mistakes that might occur if we continue on our current path without making any changes. Perform blameless post-mortems, compensate but don’t overcompensate, and insist on asking hard questions like the one posed above.